Kafka Concepts
Introduction
Kafka is a publish/subscribe message system that provides a “distributed streaming platform” as opposed to being a message broker system.
Data in Kafka is stored in order and can be read deterministically.
It implements a distributed system that protects against failures and provides scaling.
Messages and Batches
The unit of data in Kafka is called a message and works similar to a row or record in a database.
The message can have an optional bit of meta data, referred to as a key.
For efficiency, messages are written into Kafka in batches. A batch is just a collection of message, all of which are produced for the same topic and partition.
Topics and Partitions
Messages are categorised into topics, similar to radio network “channels”.
Topics and additionally broken down into a number of partitions, written to it in an append-only fashion, read in order from beginning to end.
Hence, Kafka maintains a partitioned log of messages, where each partition is an ordered, immutable sequence of records, continuously appended.
As a topic generally has multiple partitions, there is no guarantee that a message is time-ordered across the entire topic. Just only within the partition.
Partitions are a way for Kafka to provide redundancy and scalability, where each partition can be hosted on a different server.
This implies that a topic can be scaled horizontally across multiple servers to provide performance benefits.
Producers and Consumers
Producers create messages for a specific topic that by default are spread across partitions.
Consumers subscribe to one or more topics and read messages from in the order they were produced by keeping track of the message offset.
The offset is a continuously increasing integer that Kafka adds to each message as it is produced. A message in a given partition has a unique offset.
With the offset for a partition, a consumer can stop and restart without losing its place.
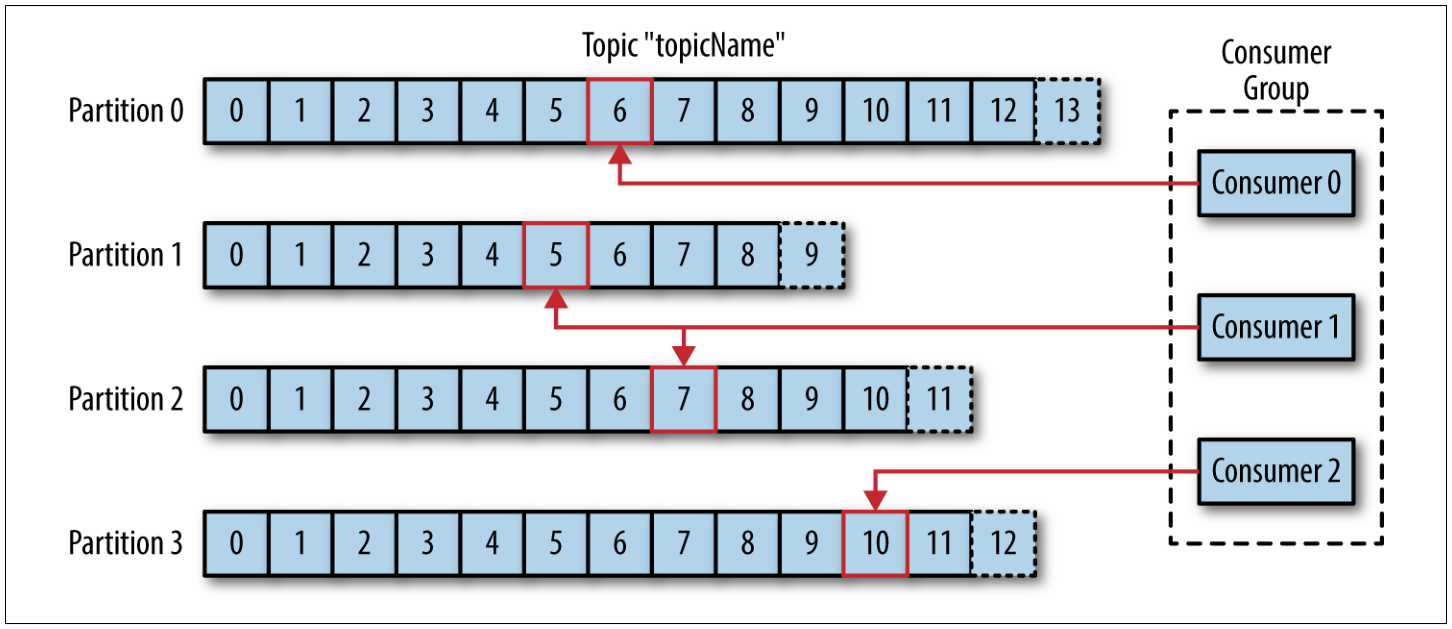
Consumers usually work as part of a consumer group, with a consumer by default only reading from one partition. In this way, consumers can scale horizontally.
If a single consumer fails, the remaining members of the group will rebalance the partitions being consumed to take over the missing member.
Brokers and Clusters
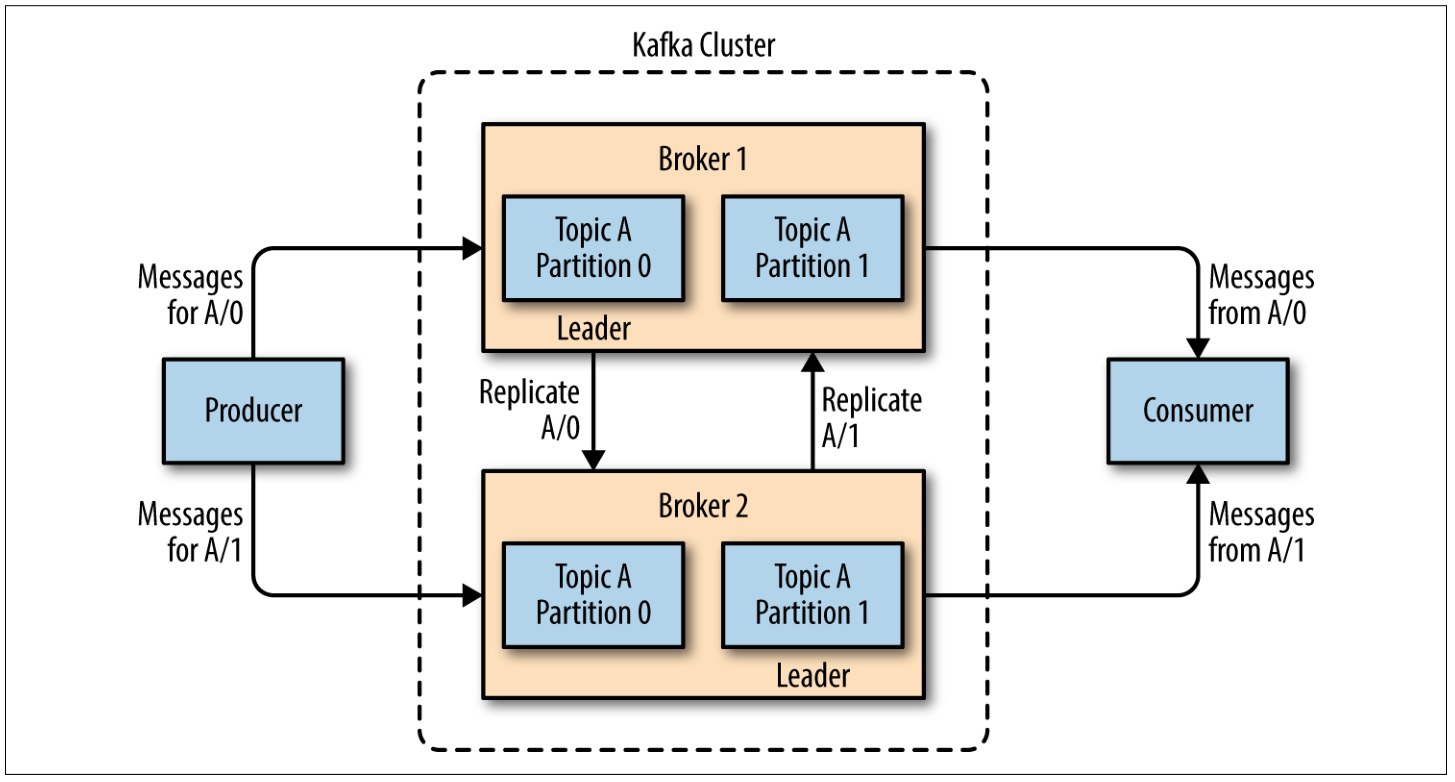
A single Kafka server is called a broker. Multiple brokers are designed to operate as part of a cluster, owning a partition.
A single broker in the cluster becomes the leader of a partition, even if the partition is assigned to multiple brokers. In this case, the leader replicates the partition, providing redundancy of messages in that partition.
Within a cluster, one broker will automatically be elected as a controller, who is responsible for administrative operations, including assigning partitions to brokers and monitoring for broker failures.
Messages are retained in Kafka with a default retention period or until the topic reaches a certain size. Expired messages are then deleted, so that a minimum amount of data is always available at any time.